Experiment Results on WebVoyager
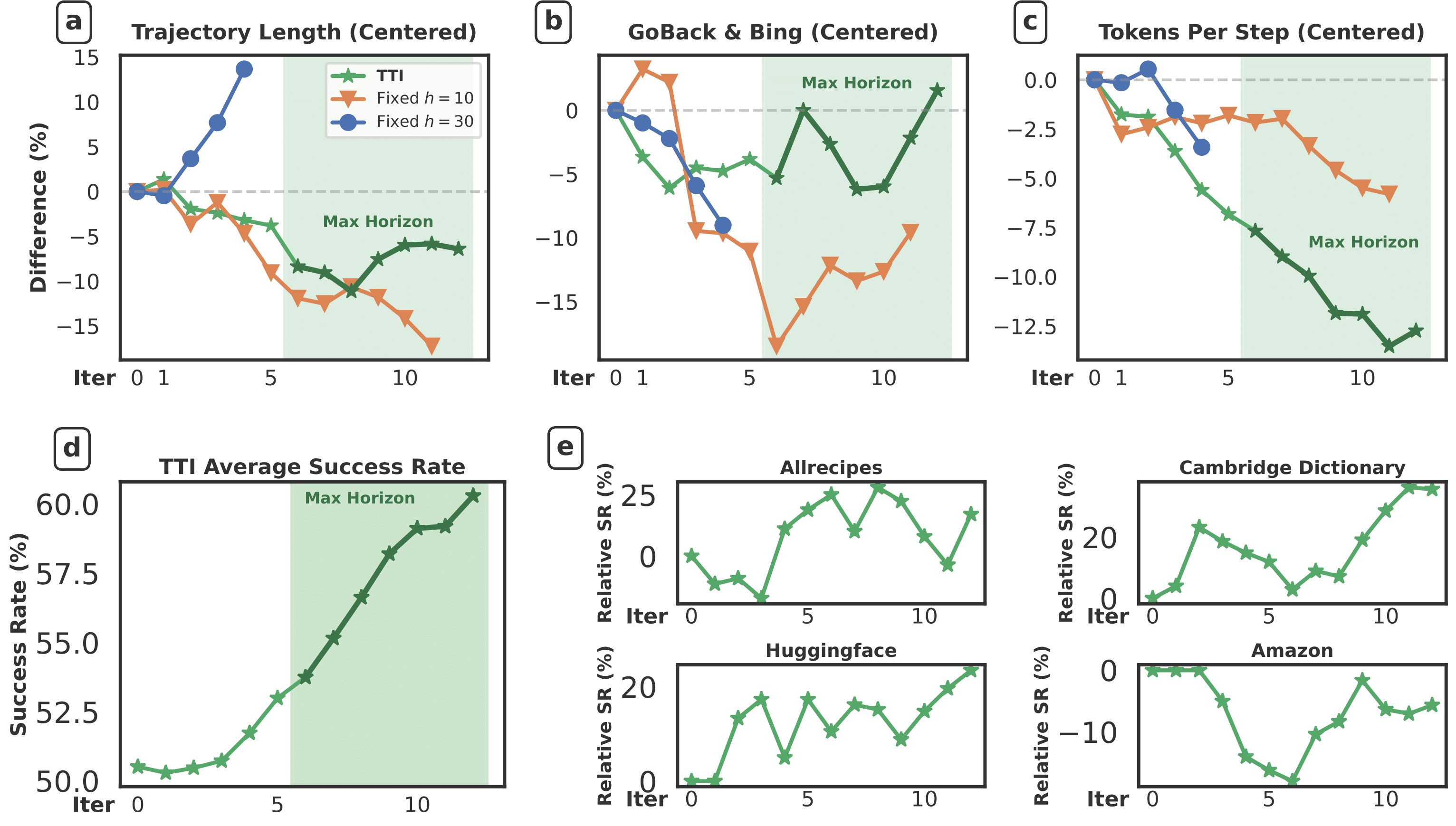
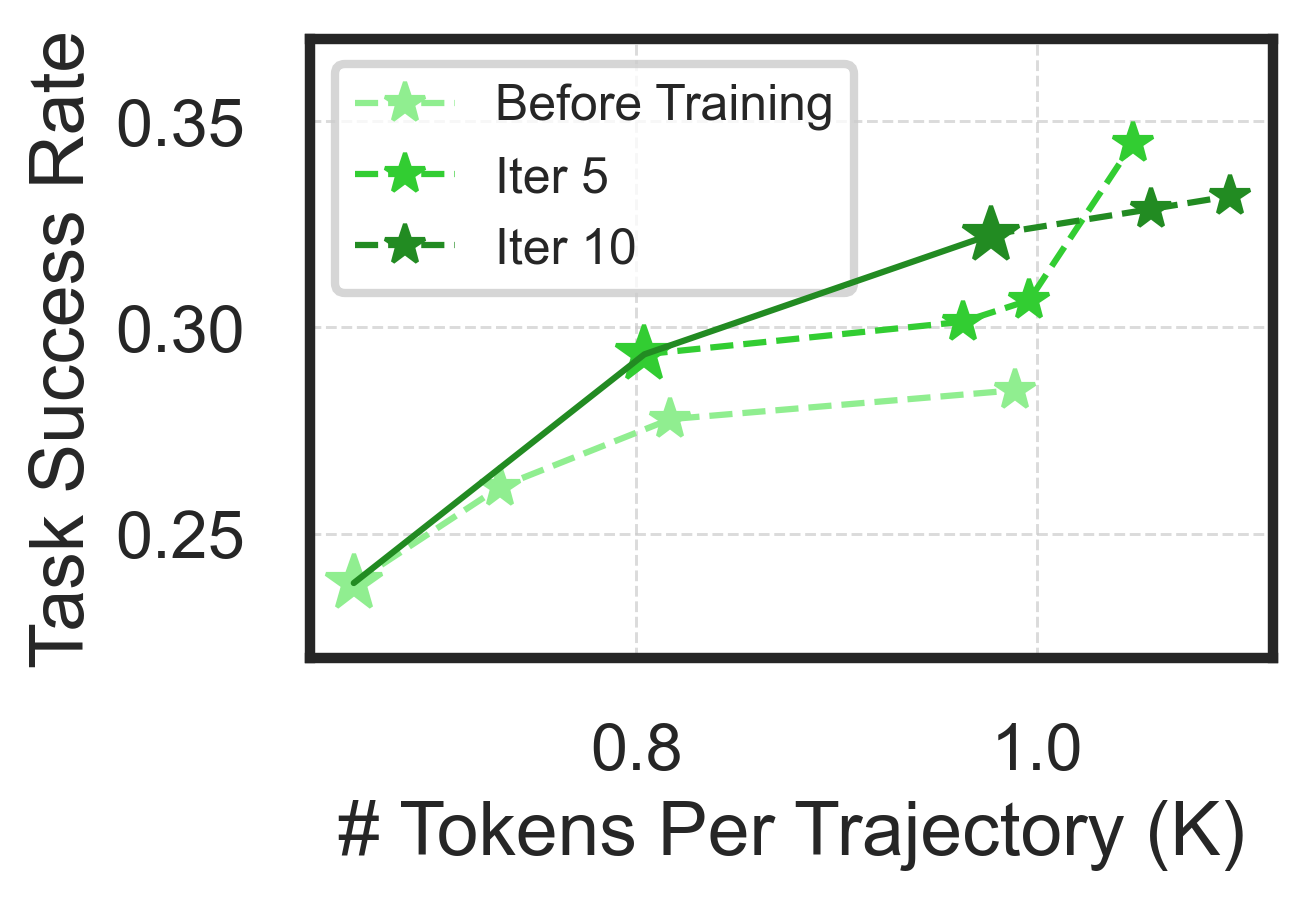
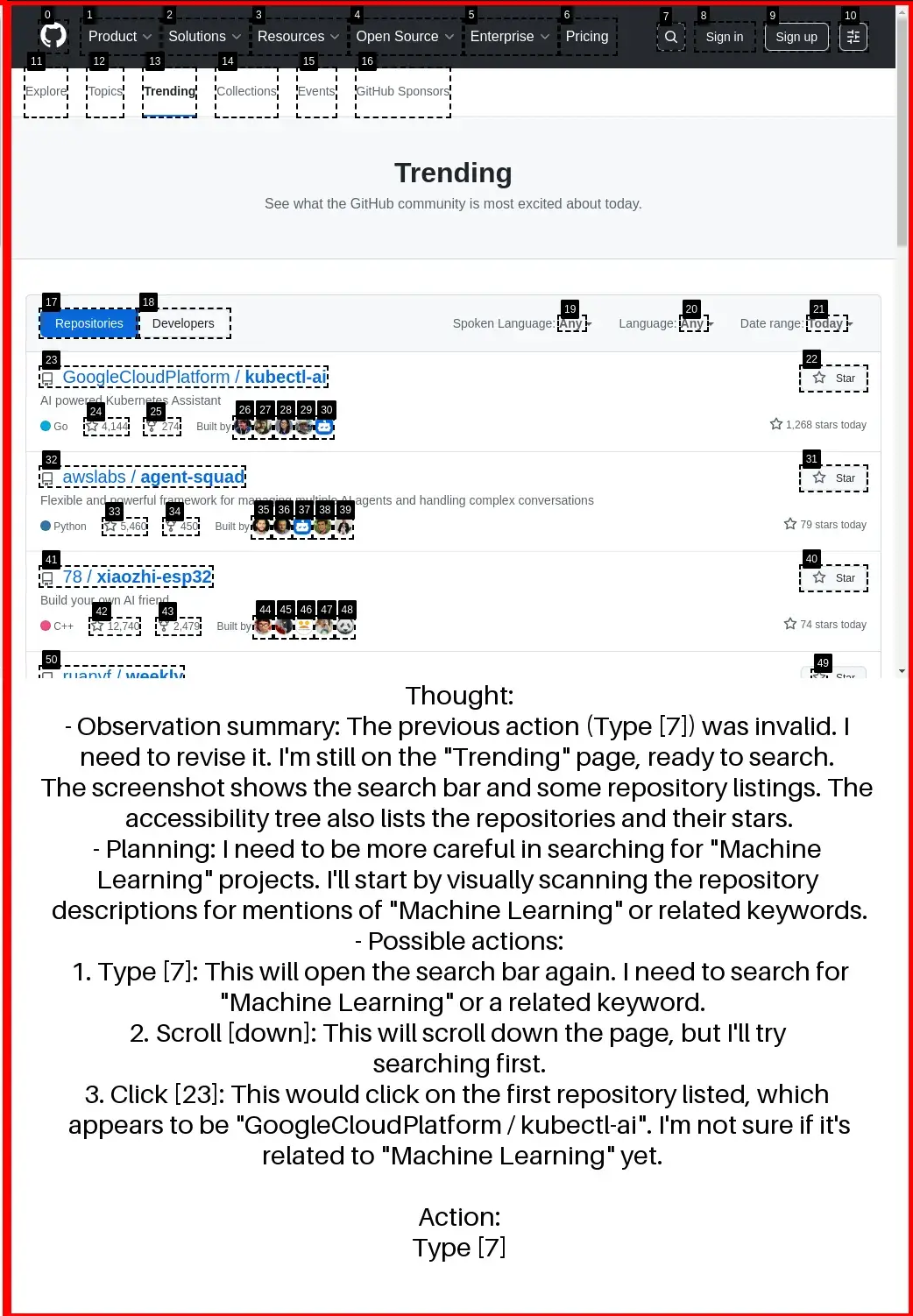
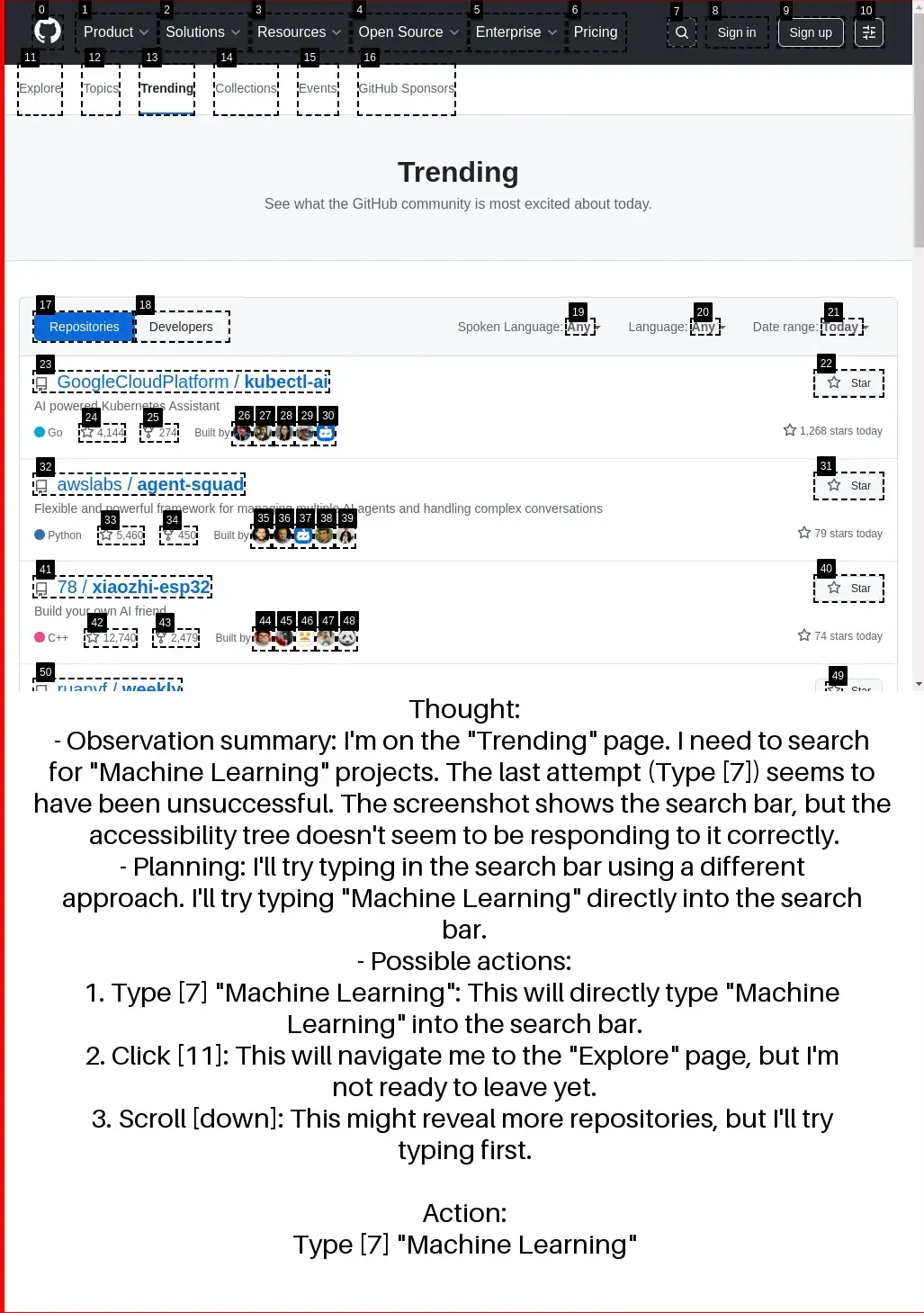
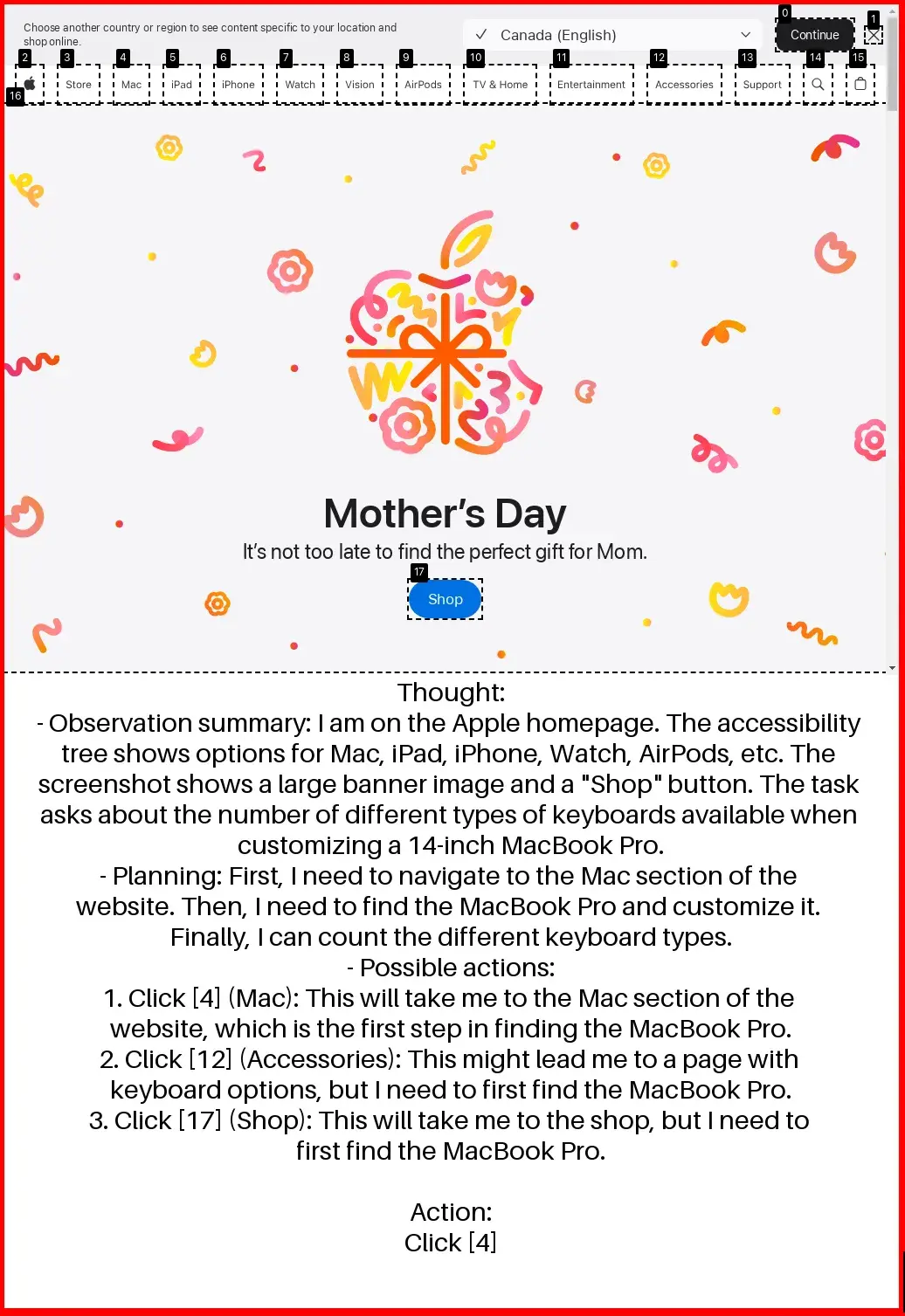
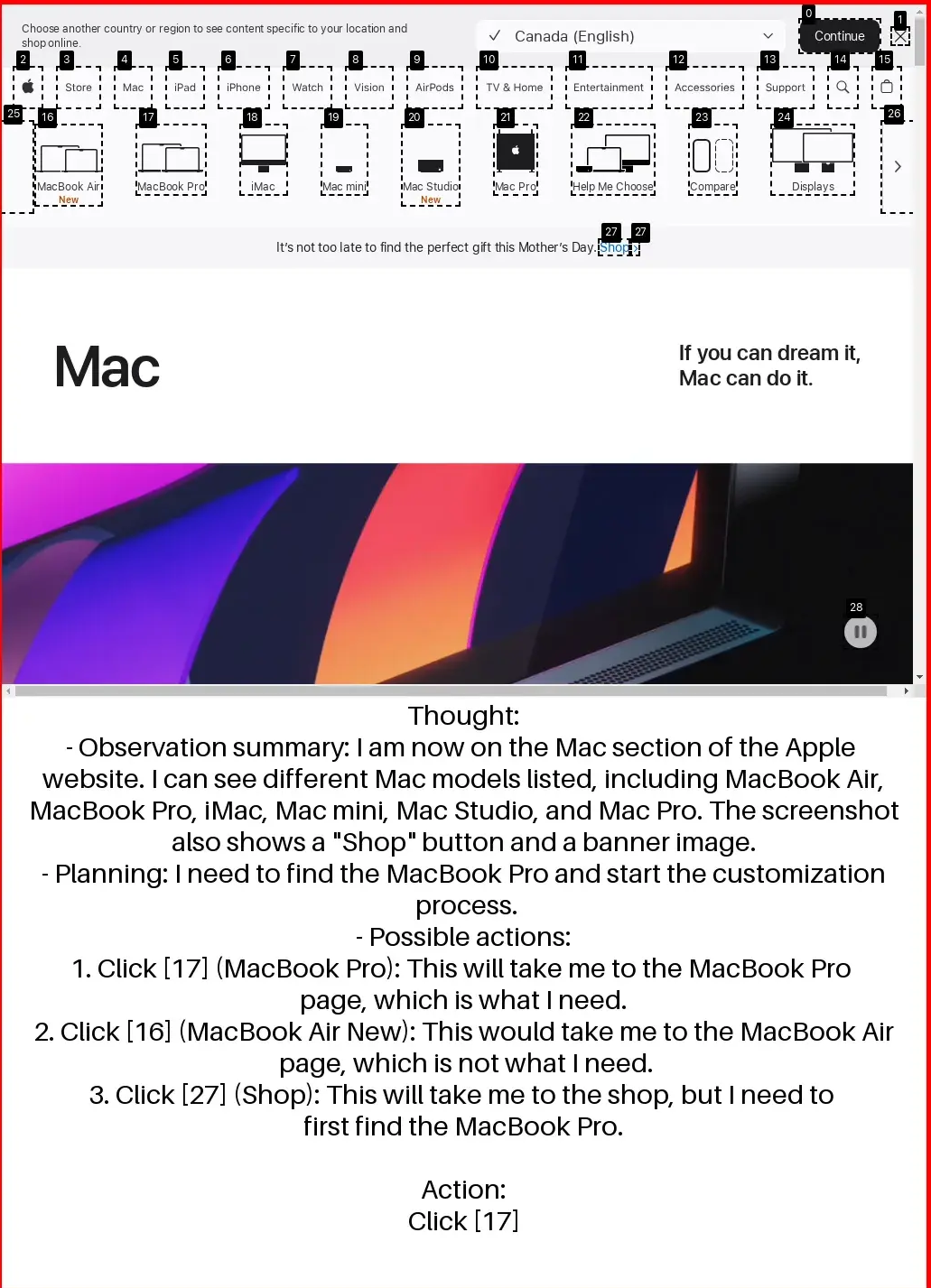
To enable large-scale training without training on the benchmark itself, we adopt synthetic task generation inspired by PAE. We first evaluate agents on WebVoyager, which consists of 427 tasks across 13 domains (we replace Google Search with Bing due to ReCaptcha issues due to ReCaptcha issues). Using Gemma 3 12B, TTI-trained agent achieves an average task success rate of 66.5%, setting a new state-of-the-art among open agents trained purely on public data. Our curriculum approach outperforms fixed 10-horizon baseline by 7.4% and fixed 30-horizon baseline by 21.3% in average accuracy.